Dev. 캡챠 인식 프로그램 개발


RPA가 만든 사소한 이야기
나의 전 직장은 2018년도 부터 RPA 를 주력 사업으로 밀고 있었다.
RPA 는 일반 유저 PC 에서 실행되는 자동화 매크로 프로그램이라고 보면 되는데, 2020년도 들어 워라밸 도입, 코로나 이슈 등을 거쳐 제기된 인력 문제에 대해, 아래 직원을 어떻게든 퇴직하게 만들어 성과를 내고 싶었던 임원들에게는 좋은 먹을거리 중 하나 였다.
겉으로 내세우는 명분은 직원들의 업무 효율 향상과 워라밸 중시. 하지만 하나하나 업무가 자동화되기 시작하면 그 업무를 보던 직원들을 재배치 하거나 재교육 하지 않고 명예 퇴직으로 유도하거나, 가스라이팅을 시전했다.
나는 현재는 웹 개발자이긴 하지만 당시 RPA 의 사업의 초기 단계에 있을 때는 RPA 개발 및 유지 보수에도 적극 참여 했다.
강렬하게 기억나는 한 장면, 엘리베이터 복도 앞 어색하게 배치된 사무용 책상.
노트북 하나만 덩그러니 있는 기묘한 모습. 여의도의 한 은행의 사무실이었다.
RPA 솔루션을 도입하면서, 자동화에 의해 대체된 과장의 자리였다. 그는 회사에서 제시한 명예퇴직을 유일하게 받아들이지 않은 한 명의 가장이었다.

회사의 명령을 곱게 받아들이지 않은 자의 말로, 복도에 배치되어 다른 직원들에게 적나라하게 노출시키는 회사의 무언의 경고,
매일 아침, 점심, 저녁마다 오가며 뵙는 그의 눈빛은 항상 총명했지만 안색은 나날이 잿빛이었다. 우리 팀이 만든 프로그램으로 인해 생긴 피해자라는 생각에 프로젝트가 끝나는 날까지 죄책감이 커져 만 갔다.
많은 사람이 오가는 엘리베이터 앞, 그 누구도 점심 식사를 권하지 않았고, 직장 동료도 애써 무시하는 촌극이 민주 사회에서 볼 수 있는 광경인가 싶었다.
천붕우출(天崩牛出)
그래도 사람이 죽으란 법은 없었나 보다, 5개월 간 자리를 지키던 과장님은 원래 본인의 자리는 아니었지만, 사무실 안으로, 우리 옆자리에 앉을 수 있었다.
사적으로는 조심스러운 미안한 감정을 가졌던 우리지만, 그 분은 개의치 않고 우리의 옆자리에서 본인 업무를 다시 찾을 수 있었다. 5개월간 본인도 득도한 것인지 오히려 프로젝트에 관심을 가지고 이거 저거 업무에 도움을 주시기도 하였다.
자동화 해야 할 업무 중 하나가 문제였는데, 정부 웹 사이트 중 크롤링 등의 봇을 차단하기 위한 캡챠 시스템이 있어서 RPA 로는 처리 가능한 범위가 아니었다.
고객사에서는 어떻게든 해결해야 한다고 난리였지만, 기획서에도, 업무 설명에도 존재 하지 않는 요구 사항이었고, 당시 우리는 해당 업무를 개발하기가 일정상 어려운 상황이었다. 결국에는 다른 조그만 업무 2개를 추가로 자동화 하기로 하였고, 그 하나의 업무는 과장님에게 돌아가게 되었다.
당시 PL 이었던 김책임은 나중에 말하길
솔직히 어딘가에 외주 넣고 그 캡챠 뚫어주는 프로그램 만들면 뭔들 못 하겠냐... 그런데 못하겠더라, 그 외주도 고객 돈 아니고 우리 돈인데, 그거 비용 감수 하면서 까지 그 양반 살 길 뺏기 싫었어...
덕분에도 과장님은 책상을 빼지 않아도 되었다, 그 이후에도 RPA 가 처리하지 못하는 어려운 업무는 과장님께 배정되었고, 우리도 죄책감을 조금씩 덜고 프로젝트를 완료 할 수 있었다.

캡챠 잔혹사
잡썰이 길었는데, 그 이후로 캡챠는 우리 RPA 프로젝트를 애먹게 했다. 개인적으로는 정부 사이트에서도 귀찮더라도 넣는 이유가 있기 때문에 욕하기 뭐했고, 앞서 과장님의 사례를 본 입장에서 딱히 귀찮을 뿐 미워할 대상이 아니었다.
모 저축은행 프로젝트 당시 우리 회사의 모 상무는 호기롭게 고객사에게 캡챠를 무력화할 소프트웨어를 만들 수 있다며 호언장담하고는 5명의 인원을 차출, 캡챠 이미지를 훈련하기 위한 TF 를 만들어 노가다를 시켰다.
당시 Google Vision 을 통한 이미지 추론이 나름 Hot 했는데, 그걸 사용해서 만들 수 있다고 판단했던 것.
결론부터 말하자면 쫄딱 망하고 외주 업체에 몇백 몇천 주고 사왔다. 훈련용 캡챠 이미지는 10만개를 넘어가고 있었고, 만들어진 모델의 테스트 결과는 2% 도 나올까 말까한 경악스런 확률, 상무는 그냥 Retry 노가다 하면 풀린다고 억지를 부려대고 있고, TF 에 차출된 직원들은 노가다 작업에 지쳐 탈주를 준비중에 있었다.
인공지능으로 뚝딱 될 수 있다고 철썩 같이 믿은 고객사는 경악할 양의 노가다, 심각한 정확도 그리고 Google Vision 접속을 위한 네트워크 정책 변경 요구 사항을 듣고는 심하게 질책했다. 당시 영업 이사의 고된 잿빛 얼굴이 아직도 기억날 정도다.
너가 함 만들어봐
그래도 아예 안 할 수는 없는 노릇이었기 때문에 나는 개인 시간을 들어 프로그램을 개발했다. 물론 회사에서도 여유 시간과 멘토를 지원해주는 등 여려모로 도움을 주어서, 여유롭게 2주간 개발을 진행했다.
요즘에는 ChatGPT 같은 대화 컨택스트나 Stable Diffusion 등 여러 시각적, 문맥적 추론 모델이 넘쳐나지만, 2019년도 당시에는 CNN(합성곱 신경망)으로 모델을 구현하는 것이 주 영역을 담당했다. 물론 지금도 여전히 신경망이긴 하지만 지금보다는 조금 Low 한 레벨이었다.
당시 대표님을 통해 알게 된 멘토분이 계셔서 그분을 통해 기본 개념을 가진 소스를 받아볼 수 있었다. 하지만 실제 업무에 쓰기에는 너무 무리였던 게 문제였다.
흥미 + 오기가 생긴 나는 새벽 잠에 주말까지 고사하고 개발에 나섰다.
나는 첫번째로 알고리즘의 맹점을 찾아 헤맸다, CNN 은 사용하기에 따라 가중치를 잘못 건들면 못쓰는 모델이 나오기 때문에, 내가 원하는 시나리오를 만들어야 했다.
두번째로는 전처리기를 개발해야 했다, 캡챠는 어찌되었던 시각 이미지이다. 이미지를 전처리 하지 못하면 알고리즘에 적용시기지도 못했다
금쪽같은 내 모델
이미지 파일을 전처리하고 알고리즘에 적용시키는 것 까지는 좋았다. 하지만 내가 원하는 시나리오 대로 흘러가지 않았는데, 아무리 해도 15% 이상의 성공률을 보이지 못했다.
6개의 숫자, 글자를 가진 이미지 중 단 한개라도 추론이 가능하다면 좋았을 텐데, 훈련용 이미지가 부족했을까? 아마도 이 단계에서 앞서 상무는 훈련 데이터를 늘리면 된다는 생각을 했던 것 같다.
내가 가진 훈련이미지는 1000개, 테스트 검증용을 빼면 900 개가 채 되지 않는 셈이다.
나는 머신러닝을 혼자 독학 하던 친구에게 도움을 청했다. 이놈은 Python 이 맘에 들지 않아서 Javascript 로 모델링 하는 미친놈이었기 때문에, 맨 처음에는 몇가지 컨셉만 공유한 채로 내가 혼자 작업하고 있었다.
철야에 힘들어 하던 나에게 몇가지 아이디어를 주었는데.
- Shuffle 을 대충 생각하지 말 것.
너가 원하는 목표에 따라 trainset 을 잘 배치해야 해, 너가 만든 시나리오나 알고리즘으로 인해 가중치가 오염되면 아무리 trainset 이 많아도 특정 문제만 잘 맞추는 모델이 되버려, 덧셈 뺄셈은 잘하는데 곱셈은 죽어도 못하는 애가 만들어 진다고
- 학습 시 성공/실패 만을 응답해주지 말고, 추론 과정에서 정답 가능성을 늘려나가는게 요점
100점 만점인 시험에서 애가 99점 받아왔다고 쳐, 이걸 성공으로 보냐 실패로 보냐로 하면 컴퓨터 입장에서는 실패인거야, 100점을 못 받은 거거든. 이럴 때 너 같으면 100점 받을 수 있는 시험, 못 받는 시험 있으면 당연히 100점 받을 수 있는 시험만 치려 하겠지, 요점은 99 점에 대한 목표 미달했을지는 몰라도 성공으로 유도 할 수 있도록 시나리오를 만들어야 해
- 머신러닝은 너의 생각보다 그렇게 똑똑하지 않으며, 어린애 달래듯이 잘 가르쳐야 한다.
사람들이 생각하는 것처럼 머신러닝은 만능이 아니더라, 알파고만 봐도 걔는 바둑만 잘해, 정작 기권하는 방법은 사람처럼 바둑일 두 개 던지는 법도 모르고 알림창만 날린다고. 아이들도 하나 가르칠때는 그 이유와 중간과정, 결과를 모두 인식시켜야만 이해한단 말이지, 하지만 머신러닝은 한 가지만 잘하면 되니까 그 한 가지 목표에만 집중한 모델을 만들려고 하지 말고 중간중간 만족할 수 있도록 보조바퀴를 달아주면서 훈련시켜줘
Python 문법이 맘에 안든다고 Javascript 로 머신러닝 개발하는 놈은 다르긴 했다, 영문 마스터에 원서부터 다 읽어대는 괴물이 조언해주니 참 와닿는 얘기들이었다. 모델을 어린아이 보듯이 하라니, 이거 참 어려운 문제였다.
그래서 만들었냐?
만들긴 만들었다. 회사에서 돈 받고 여러 군데 팔았으니까 나름대로 검증도 됐다.
갑자기 급커브를 틀었는데, 내가 이미 회사를 퇴사했기 때문에 모든 소스와 문서, 이메일을 남겨두고 나왔기 때문이다.
지금은 그냥 맨바닥에 헤딩을 해야했기 때문에, 퇴사 후에 재개발 하는데 1달 정도 시간이 걸렸다. 캡챠 서버가 필요할 때 마다 여러 Site 에 맞게 개발해야 했기 때문에 머리속에 대충 이미지 전처리 방법과 알고리즘은 기억하고 있었다.
재개발 캡챠 대상
RPA 프로젝트를 하면서 제일 많은 캡챠 서비스는 대법원의 "나의 사건검색" 서비스였다. 금융,물류,제조 마다할 거 없이 해당 서비스는 많은 업체에서 사용하고 있었는데, 해당 업무를 자동화 하기 위해서는 캡챠를 인식 할 필요가 있다.
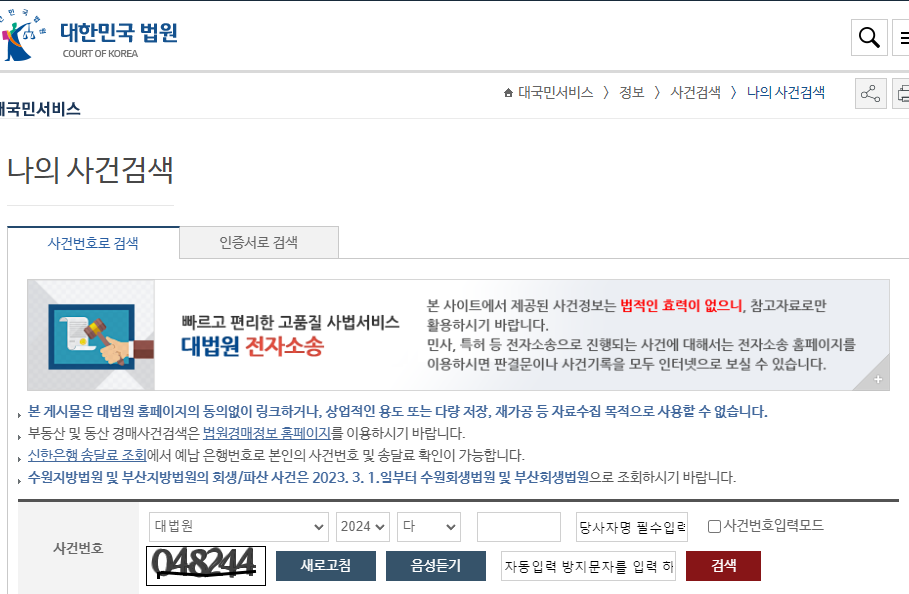
캡챠 난이도는 매우 낮은편이다, 0~9 까지의 중복가능한 아라비아 숫자 6개, 색깔로 구분되어 있거나, 글자간 폰트 차이도 없고 노이즈도 적다.
모델 훈련
1100 개의 trainset 중 test 비율은 10 퍼센트로 잡았다. 훈련용 이미지 셋은 990개, 테스트 이미지 셋은 110 개.
train/valid 간 set 은 70%, 30% 로 잡았다.
CUDNN 8.9.7.29
RTX 3080 1EA
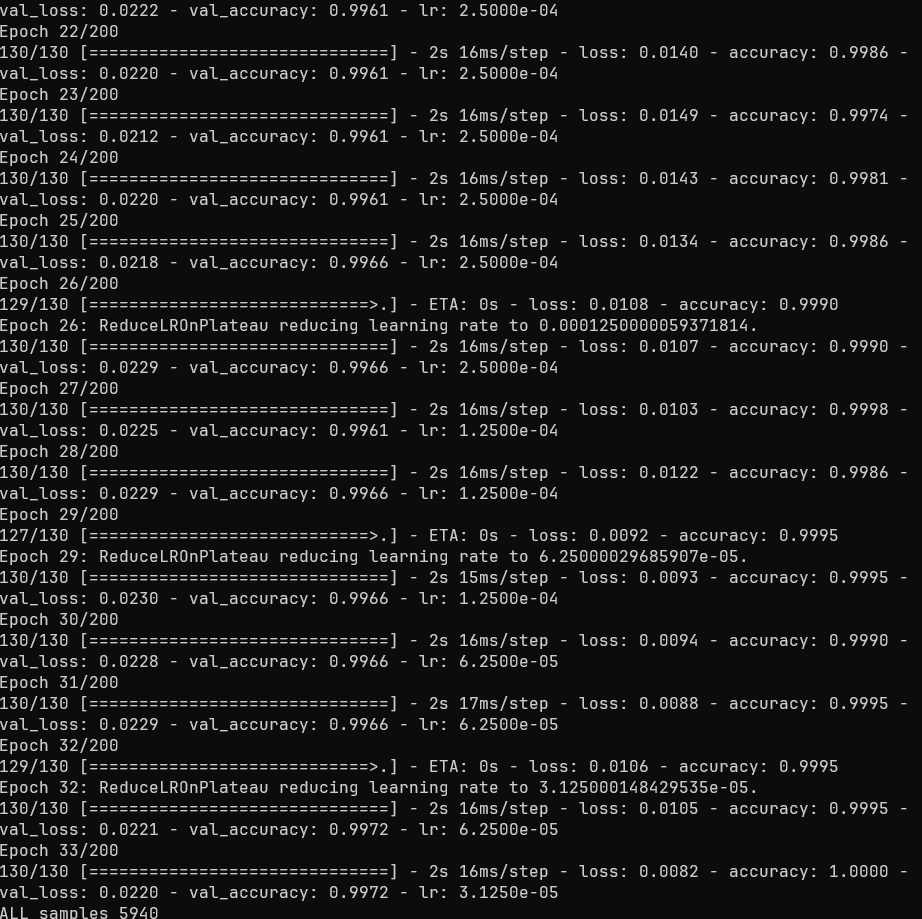
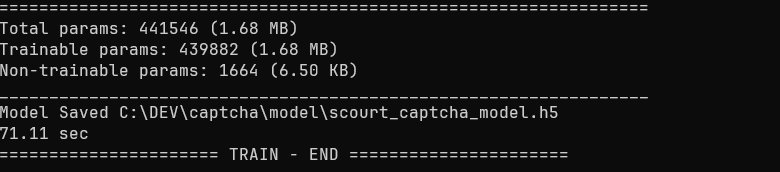
trainset 도 적고, epoch 을 200 정도로 낮게 잡은데다, 그거도 40 epoch 을 넘기지 않았다. 총 훈련 시간은 1분 내외.
역시 노가다 하면서 sweat-spot 을 찾아낸 덕분에 30분 가량 걸리던 훈련 시간을 1분대까지 줄일 수 있었다. 30분 걸리던 거도 사실은 layer 를 잘못 잡아서 삽질 한 시간이라, 숙련자라면 더욱 빠르게 가능했을 일이다.
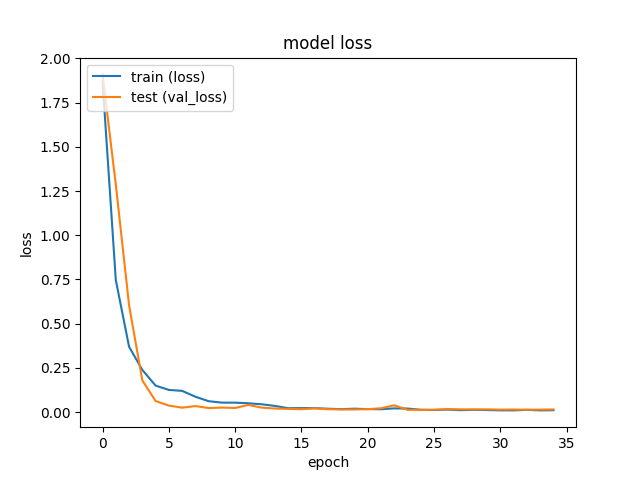
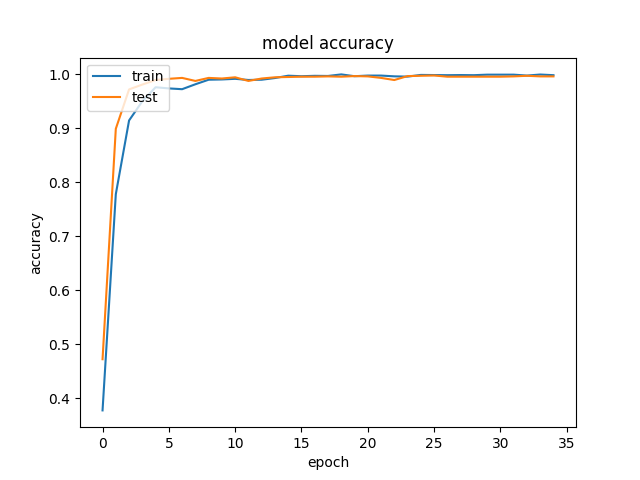
loss 와 acc 도 매우 만족스러웠다 최종 결과는 아래와 같다
loss: 0.0093 (훈련 손실값)
accuracy: 0.9995 (훈련 정확도)
val_loss: 0.0136 (검증 손실값)
val_accuracy: 0.9961 (검증 정확도)
모델 테스트
중간 개발 과정은 앞 내용보다 지루해서 탈고중에 지워버렸다. 이 글에서 중요한 건 캡챠 이미지를 인식했냐 아니냐니까
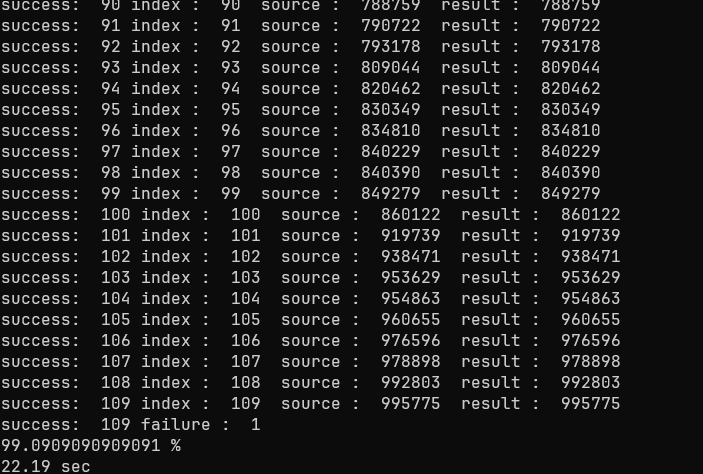
수많은 가중치 수정 노가다, trainset 셔플을 반복하면서 마의 95 퍼센트 성공률을 뚫어내고, 테스트 99퍼센트까지 확인할 수 있었다.
숫자 하나하나의 정확도로만 따지면 660 개의 숫자 중659 개의 숫자를 인식, 1개의 숫자만 실패하였으니 99.85% 로 보면 될 것이다.
회사에서 만들었던 캡챠 인식 모델보다 정확도가 높아서 놀랐다. 그때는 94퍼센트 이상을 찍어본 적이 없었기 때문이다.
실전 테스트
웹 페이지에 노출되는 캡챠 이미지는 캡챠 서버에서 무작위로 받아온다.

단순 이미지 복사를 하면 src 값이 복사되므로 기존 이미지가 아닌 새로운 이미지를 받아온다. 결국에는 캔버스를 읽어다가 base64 로 전달하는게 최선이라고 판단했다.
flask 서버를 올리고 RestAPI 를 통해 base64 로 인코딩된 이미지 바이트를 전달받아 캡챠 모델에서 predict 하도록 한다. 추가로, pyinstaller 로 빌드하여 exe 파일로 실행 가능하도록 패키징 했다
크롬 쪽 클라이언트는 크롬 확장 프로그램을 통해 flask 서버로 이미지를 전송할 수 있도록 만들었다.
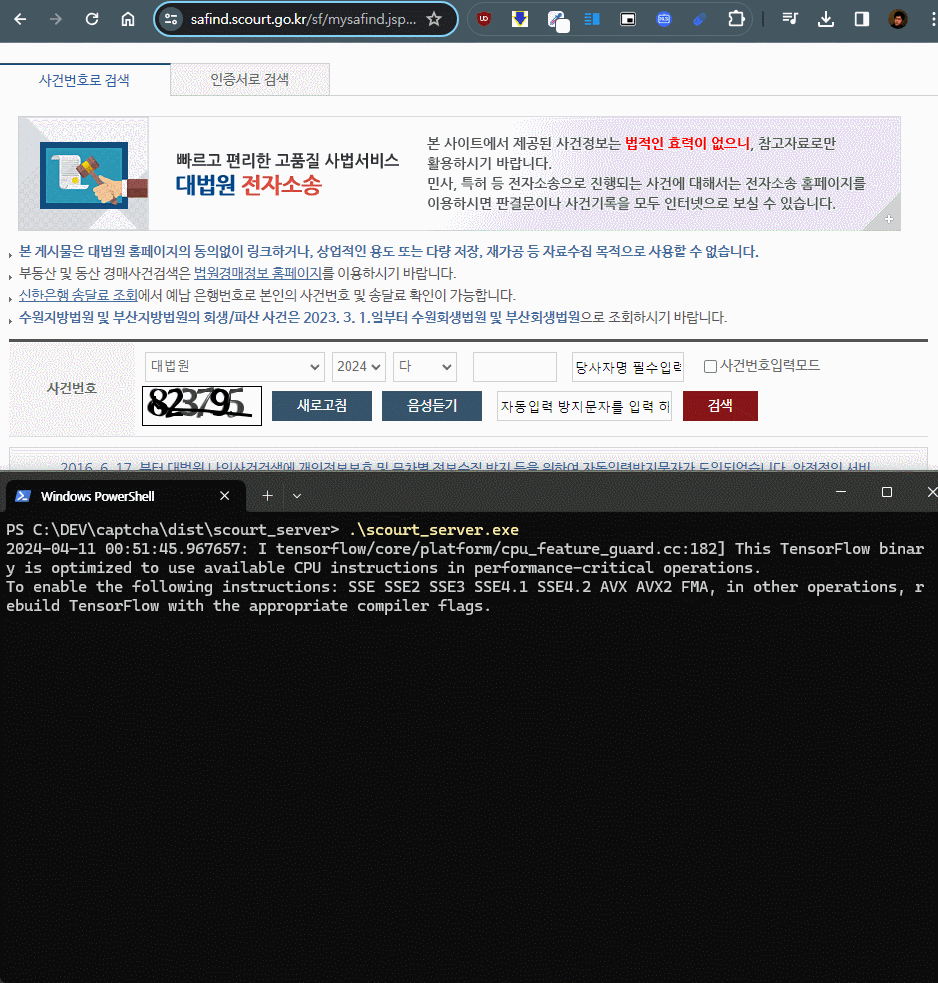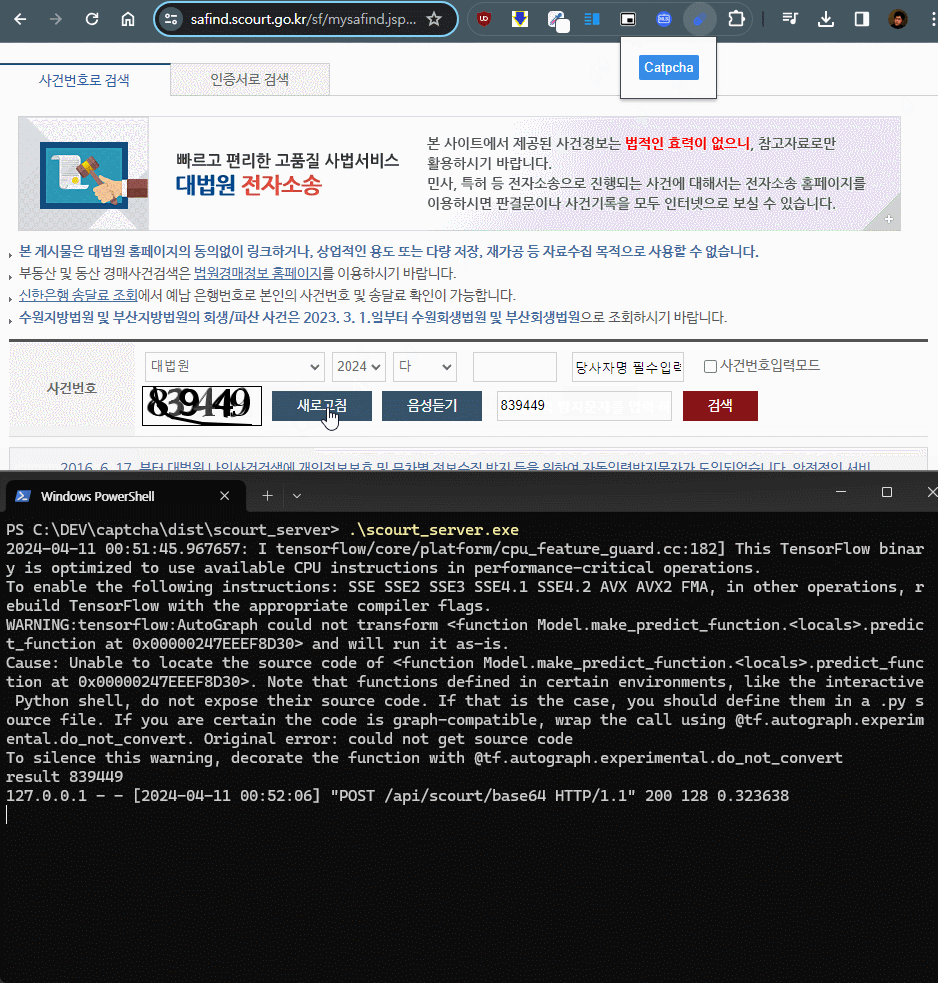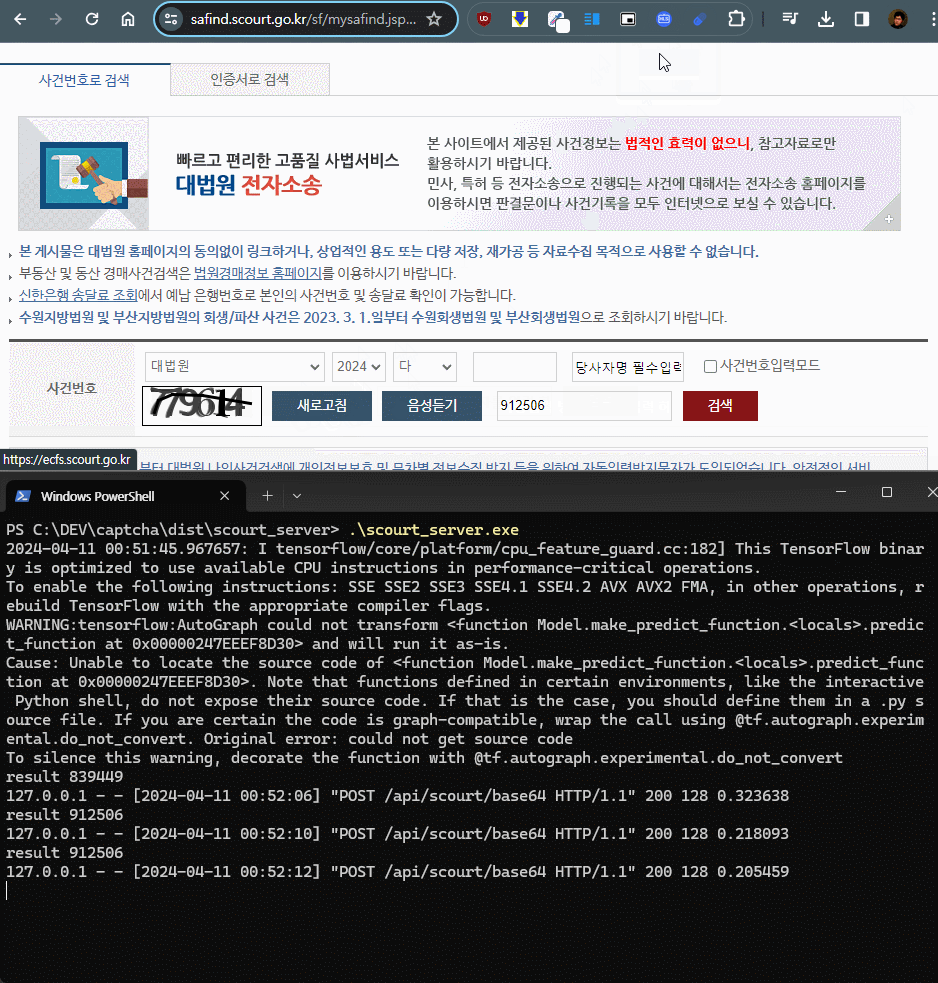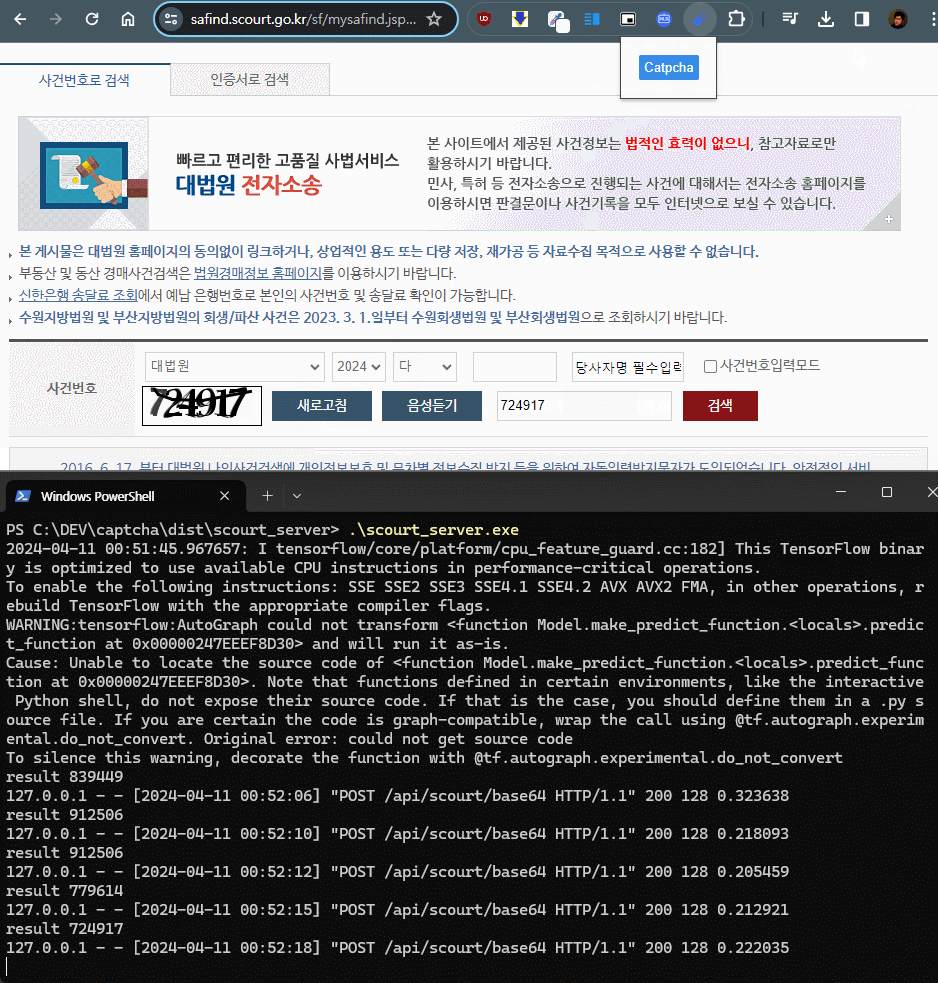
이미지 캔버스를 읽어서 서버에 전송, 처리결과를 전달받아 캡챠 입력란에 넣는 것 까지, 서버 와 확장 프로그램에 하루정도 테스트가 걸렸다.
CPU 환경에서도 매우 빠른 응답속도를 가지고 있으며, GPU 필요 없이 추론 가능하다.
앞으로의 계획
일단 대법원 뿐만 아니라 정부24, 위택스, 지로 사이트등 여러 캡챠도 테스트를 해보고 있는데, 모두 90% 이상의 나쁘지 않은 결과가 나왔다.
당장은 이걸 만들어 놓고 그냥 포트폴리오로 둘 생각만 하고 있다. 따로 상품화 시키거나 오픈소스로 풀 생각도 당장은 없다.
오늘은 이것으로 마무리 하고자 한다, 또 나중에 할게 있으면 내용을 추가할 수 있도록 하겠다.
home.needpainkiller.xyz
email : kam6512@gmail.com / needpainkiller6512@gmail.com
phone : 010-6376-6512