Dev. 성능과 유지보수를 위한 NGINX 튜닝


https://cookbook.needpainkiller.xyz/network-nginx.html
서론
Nginx 의 시대
과거에는 웹 서버라고 하면 아파치였고, WAS 까지 포함시킨다면 아파치-톰캣 구조가 국룰이었던 시대가 있었다. 하지만 모바일 시대의 여명이 다가오고 거대하고 수많은 트래픽이 네트워크에 해일처럼 몰아치자, 기존의 모놀리스화 된 어플리케이션들은 이 기세를 견뎌내야만 했다.
이렇게 수많은 요청을 분산하기 위해 어플리케이션을 MSA 로 이관하려는 움직임이 있었다. 하지만 그보다 더 빠르게 어플리케이션의 컨테이너화가 진행되면서, 대 컨테이너 시대에서 웹 서버는 우리의 예상보다 더 거대한 영역를 감당해야 하는 입장이 되었다.
풀 스택 웹 프레임워크의 혁명이었던 MEAN Stack 은 ExpressJS 를 필두로 NodeJS, JavaScript 진영에 큰 무기가 되어 주었는데, 그중에서도 백엔드 영역을 크게 넓혀나가며 Spring 원툴이던 수많은 웹 개발자들을 흡수하고 있었다. (정작 나도 지금은 거의 Spring 원툴이다.)
당시 나는 PHP 에 고통 받고 있던 고등학생이었고, PHP 특유의 괴랄한 문법에 질려버려 웹 개발을 포기하려 했었다. 때맞춰 AngularJS 가 등장하면서 그나마 한숨 놓았던 기억이 있는데, 그때 처음으로 Nginx 를 접할 수 있었다.
Ngnix 는 이미 하나의 성숙한 웹 서버 플랫폼 중 하나였고, Apache 의 1 Clinet - 1 Thread 정책이 C10K 이슈를 등에 업고 나타면서, Nginx 는 Event-Driven 방식을 채택해 적은 Thread 로도 낮은 Context Switch 비용을 내세워 많은 이들의 사랑을 받을 수 있었다.
정작 Nginx 는 본래 Apache 의 C10K 문제를 해결하기 위해 Apache 의 서브모듈로 만들어졌음을 생각하면 참 오묘하기도 하다. 많은 사람들이 오해하는 VS 구도는 애저녁부터 존재하지 않았던 셈인데,
물론 CPU 의 IPC 성능이 급증하고, HyperThreading 에서 시작한 스레드간 격리/공유의 추상화 개념이 실전에서 빛을 발하게 된 것도 큰 성장 요인 중 하나다.

Nginx 초심자에게 아주 좋은 글을 추천한다.
Nginx 의 튜닝
최근 Go 기반의 traefik 이 컨테이너 친화정책을 펴면서 많은 사랑을 받고 있지만, 여전히 Nginx 의 수요는 굳건하다, Apache 도 마찬가지고. treafik 의 약진에도 아직까지도 전통적인 웹 서버가 사랑받는 이유는 단순히 경로의존성에 의한 편애가 아니라 그 유지보수성과 충분히 입증된 성능 덕분일 것이다.
production 에서 원하는 성능을 충족시키기 위해서는 Apache 가 으레 그랬듯, Nginx 도 튜닝은 필수 불가결한 요소이다.
환경 준비
나는 Nginx 를 컨테이너로 올리는 것을 선호하지만, Docker 특유의 권한 정책이 거슬리기 때문에 직접 Source 를 build 하거나 Podman 컨테이너를 사용한다.
물론 개인적으로 Podman 은 프로덕션 환경에서 단독으로 운영하기에는 위험성이 있다고 생각하기 때문에, K8S 등의 CRI 를 따로 쓰지 않는다면 직접 Source 를 build 해서 유저 권한으로 실행하는 것을 선호한다. (80,443 포트 사용이 필요하다면 패킷을 포워딩 하는 것을 고려할 것)
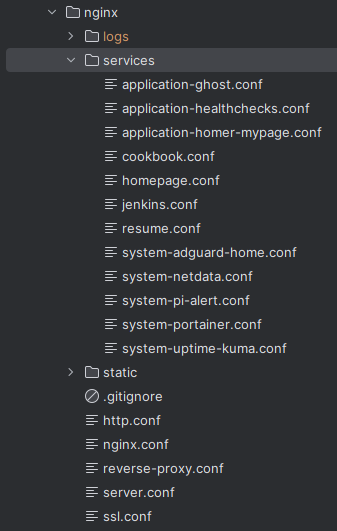
나는 Reverse-Proxy 가 필요한 서비스 영역은 따로 services 로 분리해서 include 한다. 그리고 nginx.conf 를 필두로 ssl, http 등 설정들도 따로 분리한다.
튜닝 시작
따로 cookbook 을 개설했으니, 참고하면 된다.
Linux 커널 영역
이는 컨테이너를 사용하지 않고, 베어메탈 서버에 직접 Nginx 서버를 올리는 경우에 해당된다.
웹 서버를 구성하는 Linux 서버는 예로부터 이어진 커널 튜닝이 대물림되는 국밥집 비법처럼 존재하는데, TCP 튜닝부터 시작하여 FD 튜닝까지 매우 다양하다. 여기서는 자주 사용되는 튜닝 법을 소개하고자 한다.
sysctl -a우선 커널 값 확인 부터
Queue Size
- net.core.somaxconn : 소켓 연결 대기 큐의 최대 길이
- 클라이언트의 연결 요청은 accept() 를 호출하기 전에 queue 에 쌓이는데, 이 queue 가 작으면 트래픽이 peak 하는 와중에 클라이언트의 연결 요청이 drop 될 수 있다
- Nginx 는 이미 연결을 빠르게 처리하기 때문에 이 값을 높이는 것은 큰 의미가 없을 수 있지만, 대규모 트래픽을 처리하는 서버에서는 이 값을 높이는 것이 좋다.
# default : 128
sudo /sbin/sysctl -w net.core.somaxconn="1024"
# 영구 설정
echo "net.core.somaxconn=1024" >> /etc/sysctl.conf- net.ipv4.tcp_max_syn_backlog
- 위에서 설정한 net.core.somaxconn 이 Accept queue 이라면, net.ipv4.tcp_max_syn_backlog 는 SYN backlog queue 이다.
- TCP 연결을 위한 3-way handshaking 에서 서버가 클라이언트 측으로 부터 SYN 을 받으면 상태를 SYN_RECV 로 변경, SYN backlog queue 에 저장한다.
- tcp_max_syn_backlog 는 queue 에 저장되는 최대 길이를 설정하는 것이며 너무 작은 값을 가지면 Syn flooding 공격에 취약해질 수 있다.
# default : 128
sudo /sbin/sysctl -w net.ipv4.tcp_max_syn_backlog="1024"
# 영구 적용
echo "net.ipv4.tcp_max_syn_backlog=1024" >> /etc/sysctl.conf- net.ipv4.tcp_syncookies, tcp_syn_retries, tcp_retries1
- 동일 client 에서 새로운 SYN 패킷을 수신받더라도 syn backlog queue 에 쌓지 않으므로 tcp_max_syn_backlog 설정에 도움이 된다.
- 서비스가 부하가 클 경우 응답처리가 되지 않아 retry 들이 증가, 신규 요청을 처리할 수 없게 된다.
- 이때 tcp_syn_retries 를 축소시킴으로서 신규 유입을 증가 시키고, 응답이 없을 시 불필요한 재시도를 줄이는 것이다.
sudo /sbin/sysctl -w net.ipv4.tcp_syncookies="1" # default : 0
sudo /sbin/sysctl -w net.ipv4.tcp_syn_retries ="2" # default : 5
sudo /sbin/sysctl -w net.ipv4.tcp_retries1 ="2" # default : 3
# 영구 적용
echo "net.ipv4.tcp_syncookies=1" >> /etc/sysctl.con
echo "net.ipv4.tcp_syn_retries=2" >> /etc/sysctl.con
echo "net.ipv4.tcp_retries1=2" >> /etc/sysctl.con- net.core.netdev_max_backlog : 수신 대기 큐의 최대 길이
- 패킷이 CPU로 전달되기 전에 네트워크 카드에 의해 버퍼링되는데 이를 ring buffer queue에 쌓는다. 이 값을 높이면 NIC(네트워크 인터페이스 카드)가 패킷을 수신할 때까지 대기한다.
- 이 값을 높이면 네트워크 인터페이스가 패킷을 더 많이 버퍼링할 수 있으므로 네트워크 인터페이스의 성능이 향상될 수 있다.
# default : 1000
sudo /sbin/sysctl -w net.core.netdev_max_backlog="30000"
# 영구 적용
echo "net.core.netdev_max_backlog=30000" >> /etc/sysctl.confFile
- fs.file-max
- 시스템 전체의 최대 열린 파일 디스크립터 수를 설정한다.
- 모든 네트워크 소켓은 파일로 간주되기 때문에 연결이 많아지면 파일 디스크립터 수가 늘어나게 된다.
- Nginx 는 파일 디스크립터를 많이 사용하므로 이 값을 높이는 것이 좋다.
cat /proc/sys/fs/file-max을 해보고 이미 높은 값이 설정되어 있다면 변경할 필요가 없다.
cat /proc/sys/fs/file-max
# default : 65536
sudo /sbin/sysctl -w fs.file-max="65536"
# 영구 적용
echo "fs.file-max=65536" >> /etc/sysctl.conf- hard limit / Soft limit
- nofile - max number of open file descriptors
- nproc - max number of processes
- 값 확인하기
ulimit -Hn
ulimit -Sn
# 유저별 확인
su -c "ulimit -Hn" nginx
su -c "ulimit -Sn" nginx- 값 변경하기
# /etc/security/limits.conf 에 아래 내용 추가
vi /etc/security/limits.conf
* hard nofile 65535
* soft nofile 65535
* hard nproc 10240
* soft nproc 10240
# 또는 사용자 별 지정
nginx hard nofile 65535
nginx soft nofile 65535
nginx hard nproc 10240
nginx soft nproc 10240Network (TCP, IP)
TCP 3-way-handshake 에 대한 개념이 필요하다
- net.ipv4.ip_local_port_range
- 클라이언트가 서버에 접속할 때 생성되는 소켓 생성시 사용 가능한 로컬 임시포트 범위를 설정한다.
- 이 값을 높이면 클라이언트가 서버에 접속할 때 사용하는 포트 범위가 넓어지므로 포트가 부족해지는 문제를 해결할 수 있다.
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
# 영구 적용
echo "net.ipv4.ip_local_port_range=1024 65535" >> /etc/sysctl.conf- net.ipv4.tcp_max_tw_buckets
- TIME_WAIT 상태의 소켓을 관리하는 버킷의 수를 설정한다.
- TIME_WAIT 상태의 소켓은 연결이 끝난 후에도 일정 시간 동안 유지되는 상태로, 이러한 상태가 많아지면 서버의 성능에 영향을 줄 수 있다
# default : 180000
sysctl -w net.ipv4.tcp_max_tw_buckets="1800000"
# 영구 적용
echo "net.ipv4.tcp_max_tw_buckets=1800000" >> /etc/sysctl.conf- net.ipv4.tcp_tw_reuse
- TIME_WAIT 상태의 소켓을 재사용할지 여부를 설정한다.
- 프로토콜 상 재사용이 무방한 소켓을 골라 재사용하게 되면 TIME_WAIT 상태의 소켓이 많아지는 것을 방지할 수 있다.
# default : 0
sysctl -w net.ipv4.tcp_tw_reuse="1"
# 영구 적용
echo "net.ipv4.tcp_tw_reuse=1" >> /etc/sysctl.conf- net.ipv4.tcp_timestamps
- TCP Timestamps 를 사용할지 여부를 설정한다.
- net.ipv4.tcp_tw_reuse 의 활성화를 위해서 적용해야 한다.
- 짧은 시간에 sequence number 가 overflow 되는 상황에서 새로 수신되는 패킷을 버리는 문제를 해결
- TIME_WAIT 상태의 소켓에 통신이 이루어진 마지막 시간(timestamp)를 기록
# default : 1
sysctl -w net.ipv4.tcp_timestamps="1"
# 영구 적용
echo "net.ipv4.tcp_timestamps=1" >> /etc/sysctl.conf- net.ipv4.tcp_tw_recycle
- 소켓이 TIME_WAIT 상태로 대기하는 시간을 RTO(Retransmission Timeout) 로 변경, TIME_WAIT 상태의 소켓 수를 감소시킨다.
- 이 값을 활성화하면, 서버의 성능을 향상시킬 수 있지만, NAT(Network Address Translation) 환경에서는 클라이언트로부터 SYN 패킷이 유실되는 경우가 있기 때문에 사용하지 않는 것이 좋다.
# default : 0
sysctl -w net.ipv4.tcp_tw_recycle="0"
# 영구 적용
echo "net.ipv4.tcp_tw_recycle=0" >> /etc/sysctl.conf- net.ipv4.tcp_window_scaling
- TCP Window Scaling 을 사용할지 여부를 설정한다.
- TCP Window Scaling 은 TCP 헤더에 있는 Window Size 를 확장시키는 기능으로, 네트워크 대역폭이 높은 환경에서 성능을 향상시킬 수 있다.
# default : 1
sysctl -w net.ipv4.tcp_window_scaling="1"
# 영구 적용
echo "net.ipv4.tcp_window_scaling=1" >> /etc/sysctl.conf- TCP socket 송수신(Send,Receive) buffer 사이즈 증가
- 네트웍 드라이버의 버퍼 메모리 확보
- net.core.rmem_default, net.core.rmem_max, net.core.wmem_default, net.core.wmem_max, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem
- TCP 소켓의 수신 버퍼와 송신 버퍼의 크기를 설정한다.
- 소켓의 버퍼 크기를 늘리면 네트워크 대역폭이 높은 환경에서 성능을 향상시킬 수 있다.
- 소켓의 버퍼 크기를 늘리면 네트워크 대역폭이 높은 환경에서 성능을 향상시킬 수 있다.
sysctl -w net.core.rmem_default="253952"
sysctl -w net.core.rmem_max="8388608"
sysctl -w net.core.wmem_default="253952"
sysctl -w net.core.wmem_max="8388608"
sysctl -w net.ipv4.tcp_rmem="8192 87380 8388608"
sysctl -w net.ipv4.tcp_wmem="8192 87380 8388608"
# 영구 적용
echo "net.core.rmem_default=253952" >> /etc/sysctl.conf
echo "net.core.rmem_max=8388608" >> /etc/sysctl.conf
echo "net.core.wmem_default=253952" >> /etc/sysctl.conf
echo "net.core.wmem_max=8388608" >> /etc/sysctl.conf
echo "net.ipv4.tcp_rmem=8192 87380 8388608" >> /etc/sysctl.conf
echo "net.ipv4.tcp_wmem=8192 87380 8388608" >> /etc/sysctl.conf일괄 적용하기
- cat /etc/sysctl.d/sys_tune.conf 파일에 위 설정을 일괄 저장한다
net.core.somaxconn="1024"
net.ipv4.tcp_max_syn_backlog="1024"
net.ipv4.tcp_syncookies="1"
net.ipv4.tcp_syn_retries ="2"
net.ipv4.tcp_retries1 ="2"
net.core.netdev_max_backlog="30000"
fs.file-max="65536"
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_max_tw_buckets="1800000"
net.ipv4.tcp_tw_reuse="1"
net.ipv4.tcp_timestamps="1"
net.ipv4.tcp_tw_recycle="0"
net.ipv4.tcp_window_scaling="1"
net.core.rmem_default="253952"
net.core.rmem_max="8388608"
net.core.wmem_default="253952"
net.core.wmem_max="8388608"
net.ipv4.tcp_rmem="8192 87380 8388608"
net.ipv4.tcp_wmem="8192 87380 8388608"sysctl -p명령어로 적용
파일 시스템 영역
 IT오이시이
IT오이시이
- Nginx 는 소켓처리, 로깅을 위해 파일을 읽어오는 작업이 많기 때문에 파일 시스템의 성능에 따라 Nginx 의 성능이 달라질 수 있다.
- 스크 I/O 를 최적화하기 위해 파일 시스템의 설정을 변경할 수 있다.
fstab
- filesystem 에서 사용하는 mount 옵션 설정을 수정한다.
- noatime : 파일에 접근할 때마다 파일의 마지막 접근 시간을 업데이트하지 않는다.
- nodirtime : 디렉토리에 접근할 때마다 디렉토리의 마지막 접근 시간을 업데이트하지 않는다.
- noatime, nodirtime 옵션을 사용하면 파일에 접근할 때마다 파일의 마지막 접근 시간을 업데이트하지 않아 디스크 I/O 를 줄일 수 있다.
#vi /etc/fstab
/dev/sda1 /data ext4 defaults,noatime,nodirtime 1 2
/dev/sdb1 /var/lib/docker ext4 defaults,noatime,nodirtime 1 2
# 이미 마운트된 상태에서 /data 디스크의 마운트 옵션을 변경
mount -o remount /data
# 마운트 확인
cat /proc/mountsNginx - root 영역
--- nginx.conf ---
user www-data;
worker_processes auto;
worker_rlimit_nofile 65534;
pid /run/nginx.pid;
events {
worker_connections 65534;
use epoll;
# multi_accept on;
}user
- Nginx 프로세스를 실행할 사용자를 설정한다.
- Nginx 가 Root 에서 실행되는 경우 모든 파일에 엑세스가 가능해지며, 만약 Nginx 가 모종의 이유로 공격당하거나 취약점이 발견된다면 공격자가 Root 권한을 획득할 수 있다.
- 이를 위해서 Nginx 는 Nobody 등의 특정 사용자 를 지정하는 것이 좋다.
- www-data 는 Ubuntu 에서 사용하는 사용자이며, CentOS 에서는 nginx 또는 nobody 를 사용한다.
- 권한 문제를 방지하고자 할 경우 도메인 문서 루트 디렉토리의 소유권을 www-data 로 변경해야 한다.
sudo chown -R www-data: /var/www/xxx.comworker_processes
- CPU 코어 수에 맞춰 설정하는 것이 좋으나, 수동으로 할 필요 없이"auto" 로 설정하면 알아서 CPU 코어 수에 맞춰 설정해준다.
- 물론 이는 해당 서버가 Nginx 전용 서버일 경우에만 해당되며, 다른 서비스와 함께 동작하는 경우에는 적절한 값을 설정해야 한다.
- 컨테이너 환경에서는 CPU 코어 수를 직접 지정하지 않는 이상 "auto"로 설정하는 것이 좋다.
worker_rlimit_nofile
- 실행되는 프로세스의 파일 디스크립터 수를 설정한다.
- 설정하지 않으면 기본적으로 2000인 OS 설정이 적용된다.
- 최대 제한은 일반적으로 OS에 의해 제한되며, 이 값을 무한대로 설정하는 것은 의미가 없다.
events
- 연결 처리에 영향을 미치는 지침이 지정된 구성 파일 컨텍스트를 제공합니다.
worker_connections
- worker_processes 별 동시 접속 가능한 클라이언트 수를 설정한다.
- 이 값은 worker_processes * worker_connections 값이 최대 동시 접속 가능한 클라이언트 수가 된다.
- 시스템에서 사용 가능한 소켓 연결 수에 의해 제한되므로 이 값을 무한대로 설정하는 것은 의미가 없다.
- 이 값은 서버의 메모리와 CPU 성능에 따라 적절한 값을 설정해야 한다.
- nginx 에서 모든 소켓 연결은 파일 디스크립터로 표현되며, 이 값은 worker_rlimit_nofile 값보다 같거나 작아야 한다.
ulimit -n명령어로 확인 가능하다
use
- Connection Processing method 를 설정한다.
- Nginx는 non-blocking I/O 방식을 사용하므로 요청한 connection file에 read 가능한지를 확인하기 위해 Nginx 프로세스에서 사용하는 Socket 을 지속적으로 확인한다.
- multi-thread 방식에서는 context-switching을 계속 해야 하므로 이로인한 성능 비용이 발생한다 하지만 Nginx 는 이러한 비용을 줄이기 위해 non-blocking I/O 방식을 사용한다.
- client 가 많아져 connection 이 많아지면 이러한 비용이 증가하게 되므로 이러한 비용을 줄이기 위해 Connection Processing method 를 설정한다.
- epoll, kqueue, eventport, /dev/poll, select 중 하나를 선택할 수 있다.

상세 구분은 공식 문서를 확인하
- epoll 은 리눅스에서 사용하는 방식으로, 리눅스에서는 epoll 을 사용하는 것이 좋다.
- epoll 을 사용하는 것이 가장 좋은 방식이다.
- epoll 을 사용하려면 리눅스 커널 2.6.8 이상이 필요하다.
- epoll 을 사용하려면 Nginx 를 컴파일할 때 --with-epoll 옵션을 사용해야 한다.
- FD 수가 많아지면 epoll 을 사용하는 것이 좋다.
- kqueue 는 FreeBSD, MacOS 에서 사용하는 방식이다.
- eventport 는 Solaris 에서 사용하는 방식이다.
- /dev/poll 은 Solaris, FreeBSD 에서 사용하는 방식이다.
- select 는 모든 플랫폼에서 사용 가능한 방식이다.
- poll과 select는 Nginx 프로세스에 연결된 모든 connection file을 스캔하여 read 가능한지를 확인한다.
multi_accept
공식 문서도 아님 말고 시전
- on 으로 설정하면 한 번에 여러 클라이언트의 연결을 받아들일 수 있다.
- off 로 설정하면 한 번에 하나의 클라이언트의 연결만 받아들일 수 있다.
- on 으로 설정하면 성능이 향상될 수 있는 기회가 있으나 환경에 따라 검증되지 못했고, CPU 사용량이 증가하게 된다.
- 기본적으로 off 상태이며 이 설정에 대해 여러 의견이 있지만, 앞서 설정한 worker_processes, worker_connections 만큼 많은 연결을 요하는 경우 on 으로 설정하는 것이 좋을 수 있다.
- multi_accept 를 on 으로 설정하면, 기존 커널 버전에서는 accept() 시스템 콜을 호출할 때, 커널이 클라이언트의 연결을 받아들일 수 있는 상태가 되기 전까지 Nginx 프로세스가 블로킹되어 있었지만, 이 설정을 on 으로 하면 커널이 클라이언트의 연결을 받아들일 수 있는 상태가 되기 전까지 Nginx 프로세스가 블로킹되지 않고 다른 클라이언트의 연결을 받아들일 수 있다.
- reverse proxy 환경에서는 요청을 받아들이는 서버가 여러 대 있을 수 있으므로 multi_accept 를 on 으로 설정하는 것이 좋을 수 있다.
- 그렇지 않다면 굳이 on 할 필요가 없으며, 오히려 CPU 사용량이 증가하게 되고, 커널의 TCP 스택이 병목이 발생할 수 있다.
- use 에서 kqueue 을 사용한다면, 이 지침은 수락 대기 중인 새로운 연결의 수를 보고하기 때문에 무시된다.
- 하지만 이러한 옵션을 고려해가면서 사용하기에는 Nginx 가 충분히 Single Thread 환경에서의 Event Driven 방식으로 고성능을 발휘할 수 있기 때문에, 이러한 옵션을 사용할 필요가 없으며, 통제된 환경에서의 벤치마킹을 통해 성능 차이와 이슈등을 고려하여 지정하는 것이 좋다.
- 참조 : nginx-ru 에 속한 Igor Sysoev 의 답변
Nginx - HTTP 영역
--- nginx.conf ---
http {
include /etc/nginx/http.conf;
}
--- http.conf ---
# 응답 문자셋(Content-Type)을 UTF-8 로 지정
charset utf-8;
# Nginx 버젼 노출 금지
server_tokens off;
# WebDAV 사용 금지
dav_methods off;
# 자주 접근하는 파일 대한 FD 캐시를 설정
open_file_cache max=200000 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 2;
open_file_cache_errors on;
# 리눅스 서버의 sendfile() 시스템 콜 사용
sendfile on;
sendfile_max_chunk 5m;
# Linux의 TCP_CORK 소켓 옵션을 사용할지 여부
tcp_nopush on;
# Linux의 TCP_NODELAY 소켓 옵션을 사용할지 여부
tcp_nodelay on;
# 미응답 클라이언트의 연결을 하제하고 메모리에서 해제한다
reset_timedout_connection on;
# request 의 Header, Body 를 읽는 시간 제한
client_header_timeout 10s;
client_body_timeout 60s;
# 파일 업로드 크기 제한
client_max_body_size 1G;
# 클라이언트에 응답을 전송하기 위한 타임아웃을 설정
send_timeout 2;
# 요청-응답 이후 클라이언트와 서버 사이의 연결이 유지되는 시간을 설정한다.
keepalive_timeout 30;
#클라이언트가 단일 keepalive 연결을 통해 만들 수 있는 요청 수
keepalive_requests 100000;
# proxied server 로부터 응답을 읽는 timeout 시간
proxy_read_timeout 60s;
# proxied server로 요청을 전송하는 timeout 시간
proxy_send_timeout 60s;
map $status $loggable {
# 응답코드가 200, 304인 경우에는 로그 제외
~^[23] 0;
default 1;
}
# 로그위치 설정
# HDD의 I/O를 높이기 위해 액세스 로그를 비활성화 하는 것도 추천된다.
access_log off;
# 응답코드가 200, 304인 경우에는 로그 제외
# access_log /var/log/nginx/access.log combined if=$loggable;
# 버퍼에 로그를 쌓아두고 일정 시간이 지나면 로그를 디스크에 쓰는 방식
# access_log /var/log/nginx/access.log main buffer=32k flush=1m gzip=1;
# 심각 한 오류만 로그
error_log /var/log/nginx/www_error.log crit;
# 존재하지 않는 파일에 대한 로그를 남기지 않음
log_not_found off;
# IP 차단 X
allow all;
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
# 캐싱
#proxy_buffering on;
#proxy_buffer_size 4k;
#proxy_buffers 8 4k;
#proxy_cache_min_uses 1;
#proxy_cache_methods HEAD, GET;
#proxy_cache_key "$scheme$host$request_uri$cookie_user";
#proxy_cache_valid 404 1m;
#proxy_cache_valid 500 502 504 5m;
#proxy_cache_valid 200 10;charset
- Nginx 가 사용하는 문자 인코딩을 설정한다.
- "Content-Type" 응답 헤더 필드에 지정된 문자 세트를 추가하거나 변경한다.
server_tokens
- off 로 설정하여 오류 페이지와 응답
Server헤더에 Nginx 버전 정보와 OS 정보를 제외시킨다. 대신 nginx 로만 표시된다. - 보안상의 이유로 Nginx 버전 정보를 노출시키지 않는 것이 좋다.
dav_methods
- WebDAV 모듈에서 사용할 수 있는 HTTP 메서드를 설정한다.
- 외부에서 접속하여 WebDAV 를 사용하지 않는다면 설정할 필요가 없다.
FD 캐시 (open_file_cache)
- 자주 접근하는 파일 대한 FD 캐시에 대한 설정
- 성능을 향상시킬 수 있지만, 파일이 동적으로 자주 변경되는 경우에는 적합하지 않으며
- 실제 성능 향상에 대해서는 벤치마킹을 통해 확인해야 한다.
- FD (파일 디스크립터)는 다음과 같은 정보를 가진다.
- 열린 파일 설명자, 크기 및 수정 시간
- 디렉토리 존재에 관한 정보, 파일이 존재하는 지 아니면 권한으로 인해 읽을 수 없는지 여부
open_file_cache
- 자주 접근하는 파일 대한 FD 캐시의 최대 크기를 설정한다.
- max : 캐시의 최대 요소 수
- inactive : 캐시를 엑세스 하지 않은 시간(초)이 지난 후 제거 된다.
open_file_cache_valid
- open_file_cache 요소의 유효성을 검사해야 하는 시간을 설정한다.
open_file_cache_min_uses
- FD가 캐시에서 열려 있는 상태를 유지하는 데 필요한 open_file_cache 디렉티브의 비활성 매개 변수로 구성된 기간 동안의 최소 파일 액세스 수
open_file_cache_errors
- open_file_cache에 의한 파일 조회 오류의 캐싱 여부를 설정한다.
sendfile

- 리눅스 서버의 sendfile() 시스템 콜을 사용할지 여부를 설정한다.
- sendfile() 은 기본적으로 read() + write() 보다 빠르다.
- 커널에서 최적화된 알고리즘을 통해 파일 전송 속도가 빨라지며 전송에 대한 메모리 사용이 감소되어 고성능 웹서버 구축에 매우 중요한 옵션이다.
- 기본적으로 NGINX는 파일 전송 자체를 처리하고 파일을 전송하기 전에 버퍼에 복사한다. sendfile directive를 활성화하면 데이터를 버퍼에 복사하는 단계가 없어지고 커널 단계에서 한 파일 디스크립터에서 다른 파일 디스크립터로 데이터를 직접 복사할 수 있다
sendfile_max_chunk
- sendfile() 시스템 콜을 사용할 때 한 번에 전송할 수 있는 최대 데이터 양을 설정한다.
- 하나의 빠른 연결이 워커 프로세스를 완전히 차지하는 것을 방지하기 위해 sendfile_max_chunk directive를 사용하여 단일 sendfile() 호출에서 전송되는 데이터의 양을 1MB로 제한할 수 있다
tcp_nopush
- Linux의 TCP_CORK 소켓 옵션을 사용할지 여부를 설정한다.
- sendfile을 사용하는 경우에만 옵션이 활성화 된다.
- sendfile을 통해 Data chunk 를 로드한 후 HTTP 응답 헤더를 하나의 패킷으로 병합한다
- 이후 응답 헤더와 파일의 시작을 하나의 패킷으로 전송하게 되어 네트워크 대역폭을 절약할 수 있다.
- 하지만, 이 옵션을 사용하면 데이터가 버퍼링되어 전송되기 때문에 실시간 데이터 전송 (스트리밍) 에는 적합하지 않을 수 있다. 벤치마킹이 필요한 부분.
tcp_nodelay
- Linux의 TCP_CORK 소켓 옵션을 사용할지 여부를 설정한다.
- sendfile을 사용하는 경우에만 옵션이 활성화 된다.
- sendfile을 통해 Data chunk 를 로드한 후 HTTP 응답 헤더를 하나의 패킷으로 병합한다
- 이후 응답 헤더와 파일의 시작을 하나의 패킷으로 전송하게 되어 네트워크 대역폭을 절약할 수 있다.
- 하지만, 이 옵션을 사용하면 데이터가 버퍼링되어 전송되기 때문에 실시간 데이터 전송 (스트리밍) 에는 적합하지 않을 수 있다. 벤치마킹이 필요한 부분.
tcp_nodelay
- 연결이 keep-alive 상태로 전환될 때 TCP_NODELAY 소켓 옵션을 사용할지 여부를 설정한다.
- SSL 연결, 버퍼링되지 않은 프록시 및 WebSocket 프록시에서도 활성화된다.
- 본래 느린 네트워크에서 작은 패킷의 전송 딜레이 문제를 해결하기 위해 설계된 Nagle의 알고리즘을 재정의하는 것을 허용하는 것이며
- 여러 개의 작은 패킷을 더 큰 패킷으로 통합하여 200ms 지연된 상태로 패킷을 전송한다. 요즘에는 큰 정적 파일을 서비스할 때 패킷 크기에 상관없이 데이터를 즉시 보낼 수 있기 때문에, ssh, 온라인 게임, VoIP 등의 실시간 데이터 전송에는 적합하지 않다.
- 이 옵션을 사용하면 데이터가 버퍼링되지 않고 전송되기 때문에 실시간 데이터 전송 (스트리밍) 에 적합하다.
reset_timedout_connection
- keepalive_timeout 이 지난 후 클라이언트가 응답하지 않을 때 연결을 닫을지 여부를 설정한다.
- 또한 기본적으로는 연결과 관련된 메타정보가 메모리에 남아있게 되는데 이를 해제하여 메모리를 확보할 수 있다.
- default : off
client_header_timeout
- 클라이언트 요청 헤더를 읽기 위한 타임아웃을 정의한다. 이 시간 내에 클라이언트가 전체 헤더를 전송하지 않으면 408(Request Time-out) 오류와 함께 연결을 닫는다
- client_body_timeout 설정과 함께 DDos 의 L7 공격중 하나인 Slow Post DDos 공격을 방지할 수 있다.
- default : 60s
client_body_timeout
- 클라이언트 요청 본문을 읽기 위한 타임아웃(timeout)을 정의한다.
- 클라이언트가 이 시간 내에 아무것도 전송하지 않으면, 요청은 408(Request Time-out) 오류와 함께 연결을 닫는다.
- DDos 의 L7 공격중 하나인 Slow Post DDos 공격을 방지할 수 있다.
- 하지만 실제 파일 업로드 크기가 큰 경우에는 이 값을 적절하게 조정해야 한다.
- default : 60s
client_max_body_size
- 클라이언트에 응답을 전송하기 위한 타임아웃을 설정. 이 시간 내에 클라이언트 측에 응답이 전송되지 않으면 연결이 종료된다.
- DDOS 공격은 대부분 전송에만 치중되고 응답은 거의 처리하지 않으므로 요청만 보내고 응답을 받지 않는 경우가 많다. 이런 공격을 대비하여 작은 값으로 설정할 수 있으나, 실제 서비스에서는 적절한 값을 설정해야 한다.
- default : 60
keepalive
- 클라이언트의 연결 요청이 끝난 후에도 연결을 유지하는 것을 keepalive 라고 한다.
- nginx 가 reverse proxy 로 사용되는 경우, upstream 서버와의 연결을 유지하기 위해 keepalive 를 사용할 수 있다.
- nginx 는 요청이 들어오면 클라이언트와 reverse proxy 사이 2번의 3-way-handshake 를 만들어야 하기 때문에 성능 저하가 발생할 수 있다.
- 그에 더에 연결 종료를 위한 4-way handshaking 이 자주 발생한다면 대규모 트래픽을 관리하는 입장에서 timewait 시간동안 제거되지 않는 socket 이 발생하므로 local port 가 부족해지는 문제가 발생할 수 있다.
- keepalive 를 유지하는 것은 리소스 비용을 감수하고서라도 클라이언트간 통신이 매우 잦을 때 사용하는 것이 졸지만, Nginx 프로세스 입장에서는 연결중인 Connection 을 통한 요청이 있을 때까지 기다려야 하는 문제가 생긴다.
- 단일 클라이언트 보다 다수의 클라이언트를 상대로 하는 유동 트래픽이 많을 경우에는 keepalive 가 높으면 타 클라이언트가 연결을 맺을 수 없는 문제가 발생할 수 있다.
keepalive_timeout
- 요청-응답 이후 클라이언트와 서버 사이의 연결이 유지되는 시간을 설정한다.
- 여러차례의 요청을 보내는 경우에는 keepalive_timeout 을 높게 설정하여 세션을 유지함으로서 TCP 3-way handshake을 줄이고 timewait 소켓 생성을 줄일 수 있다.
- timewait 소켓 상태는 리눅스 커널에서 TCP 연결을 끊은 후에도 일정 시간 동안 유지되는 상태로, 이러한 상태가 많아지면 서버의 성능에 영향을 줄 수 있다.
- keepalive_timeout 을 높게 설정하면 성능이 향상될 수 있지만, 클라이언트와 서버 사이의 연결이 계속 유지되므로 서버의 리소스를 많이 사용하게 된다.
keepalive를 설정하여 worker 프로세스에 대해 열려있는 upstream 서버에 대한 keepalive 연결 수를 지정할 수 있다.- default : 75
keepalive_requests
- 클라이언트가 단일 keepalive 연결을 통해 만들 수 있는 요청 수
- 기본값은 100, 높은 값을 지정하여 단일 클라이언트에서 많은 수의 요청을 보내는 과부하 테스트하는 데 사용할 수 있다.
- default : 100
proxy_read_timeout
- proxied server 로부터 응답을 읽는 timeout 시간
- 전체 응답 전송 timeout 시간이 아니라 두개의 연속적인 읽기 작업 사이의 timeout 시간을 의미한다
- 지정한 시간안에 proxied server가 아무것도 전송하지 않으면 connection을 닫는다.
- default : 60s
proxy_send_timeout
- proxied server로 요청을 전송하는 timeout 시간
- 전체 응답 전송 timeout 시간이 아니라 두개의 연속적인 쓰기 작업 사이의 timeout 시간을 의미한다
- 지정한 시간안에 proxied server가 아무것도 수신하지 않으면 connection을 닫는다.
- default : 60s
로그
access_log
- 로그는 디스크 I/O 를 많이 사용하므로 HDD의 I/O를 높이기 위해 액세스 로그를 비활성화 하는 것도 추천된다.
access_log off;- 혹은 로그를 쌓아두고 일정 시간이 지나면 로그를 디스크에 쓰는 방식으로 로그를 관리할 수 있다.
access_log /var/log/nginx/access.log main buffer=32k flush=1m gzip=1;- 응답코드가 200, 304 인 경우에 로그를 제외하고 싶을 때는 다음과 같이 설정할 수 있다.
map $status $loggable {
~^[23] 0;
default 1;
}
access_log /var/log/nginx/access.log combined if=$loggable;error_log
- error 로그는 off 가 불가능 하다
- 만약 로그를 남기고 싶지 않다면 다음과 같이 설정할 수 있다.
error_log /dev/null emerg;- 심각한 오류만 로그
error_log /var/log/nginx/www_error.log crit;- 존재하지 않는 파일에 대한 로그를 남기지 않음
- 404 에러가 발생할 때마다 로그를 남기는 것은 불필요한 로그를 남기게 되므로, 존재하지 않는 파일에 대한 로그를 남기지 않도록 설정하는 것이 좋다.
- 이를 위해 log_not_found 옵션을 off 로 설정한다.
log_not_found off;캐시
- 캐싱을 사용하면 클라이언트의 요청에 대한 응답을 캐시에 저장하여 다음 요청에 대한 응답을 빠르게 할 수 있다.
- 캐시를 사용하면 서버의 부하를 줄일 수 있으나, 캐시를 사용할 때는 캐시의 유효 시간을 설정해야 한다.
- HEAD, GET 은 기본 캐시 메소드로 설정되어 있다.
- 정적 리소스 파일을 캐시하는 것은 권장하지만, upstream 을 이용한 reverse proxy 환경에서는 캐시를 사용하는 것을 권장하지 않으며, WAS 측에서 캐시를 사용하는 것이 좋다.
- 일반적으로 정적 리소스 파일은 브라우저 측에서 캐시를 하고 있기 때문에 큰 성능 차이가 없을 수 있다.
proxy_buffering
- upstream 서버로 요청을 보내고 응답을 받을 때, 응답을 버퍼링할지 여부를 설정한다.
- NGINX가 서버로부터 받은 응답을 내부 버퍼에 저장하고 있다가 전체 응답이 버퍼링될 때까지 클라이언트 측에 데이터 전송을 하지 않는다.
Nginx - upstream 영역
upstream backend {
ip_hash;
keepalive 100;
server backend.xxx.com:8080;
}ip_hash
- 클라이언트의 IP 주소를 해싱하여 동일한 클라이언트는 항상 동일한 서버로 연결되도록 한다.
- 이를 통해 세션 유지를 위한 로드밸런싱을 할 수 있다.
- 이 옵션을 사용하면 세션 유지를 위한 로드밸런싱을 할 수 있으나, 특정 클라이언트가 계속해서 같은 서버로 연결되기 때문에 특정 서버에 부하가 집중될 수 있다.
- 따라서, 특정 서버에 부하가 집중되는 것을 방지하기 위해 서버의 수를 늘리거나, 다른 로드밸런싱 방식을 사용하는 것이 좋다.
keepalive
- upstream 서버와의 keepalive 연결 수를 지정한다.
- upstream 서버에 대한 연결에 Nginx 는 기본적으로 HTTP/1.0 을 사용하므로 서버측 종료요청에
Connection: close헤더를 보내게 된다. - 그렇게 되면 서버측에서는 keepalive 연결을 유지하지 않게 되어 다음 요청에 대해 다시 3-way-handshake 를 수행하게 되는데 keepalive 설정이 무의미해진다.
- location 영역에서 아래 설정을 추가하여 keepalive 연결을 유지할 수 있다.
proxy_http_version 1.1;
proxy_set_header "Connection" "";Nginx - location 영역
- 웹 정적 리소스들 (이미지, CSS, JS 등)에 대한 access_log 를 비활성화 하는 것이 좋다.
location ~* \.(?:jpg|jpeg|gif|png|ico|woff2|js|css)$ {
access_log off;
}DDOS 초기 공격 대응
 denji
denji- 일반적인 DDoS 방어와는 거리가 멀지만 소규모 DDos 공격을 방어하기 위한 설정을 적용할 수 있다.
# IP 당 연결 수 제한 (IP 당 10개의 연결을 허용)
limit_conn_zone $binary_remote_addr zone=conn_limit_per_ip:10m;
# IP & 시간 당 요청 수를 제한 (초당 30개의 요청을 허용)
limit_req_zone $binary_remote_addr zone=req_limit_per_ip:10m rate=30r/s;
server {
limit_conn conn_limit_per_ip 10;
limit_req zone=req_limit_per_ip burst=10 nodelay;
}
# 클라이언트 요청 헤더 읽기용 버퍼 크기
client_header_buffer_size 3m;
# 클라이언트 요청 body 크기가 버퍼 크기보다 큰 경우 임시 파일에 쓴다
client_body_buffer_size 128k;
# 클라이언트 요청에서 읽을 대형 헤더의 최대 버퍼 수 및 크기
large_client_header_buffers 4 256k;
# 클라이언트 요청 헤더 읽기 시간 제한
client_body_timeout 60s;
client_header_timeout 10s;limit_conn_zone / limit_conn
- limit_conn_zone 지시어는 클라이언트 IP 주소를 해싱하여 클라이언트 당 연결 수를 제한하는데 사용된다.
limit_req_zone / limit_req
- limit_req_zone 지시어는 시간 당 요청 수를 제한하는데 사용된다.
- rate=5r/s 는 초당 5개의 요청을 허용한다는 의미이다.
그 외 방법
- SSL 을 적용시켜 HTTP2 또는 더 나아가 HTTP3/QUIC 를 사용하면 성능 향상을 기대할 수 있다.
- HTTP 2 부터는 TCP 영역보다 높은 단계의 Hand Shake 가 이루어지고, QUIC 부터는 UDP 기반의 동시 통신이 이루어지기 때문에, 앞서 처리한 튜닝 못지 않은 성능향상을 기대해 볼 법 하다
- Nginx Plus 를 사용하면 더 많은 기능을 사용할 수 있으며, 성능 향상을 기대할 수 있다.
- 유료 솔루션인 Nginx Plus 에서는 JWK 나 프록시 강화 등, WAS 필요 없이도 제공 가능한 기능들이 많다
- Thread Pool 사용하기
- 아직 현업에서 사용한 적은 없어 넣지는 않았지만, 실제 Thread Pool 을 이용한 성능 향상 기법들이 많이 소개되고 있으니 참고해 볼 법 하다.
참조
 Web Team
Web Team Web Team
Web Team

 bangu4
bangu4 GodNR
GodNR IT오이시이262588213843476
IT오이시이262588213843476

